이번에 소개할 논문은 Motion Transfer 분야의 SOTA 기법인 Liquid Warping GAN with attention : A Unified Framework for Human Image Synthesis이다.
샹하이 공대에서 쓴 논문이며, 현재 CV 분야 최고의 저널 중 하나인 IEEE TPAMI 리뷰를 받고 있다고 한다.
개인적으로 상당히 많이 돌려본 코드의 논문이며 현재 관련 기법 중에서는 제일 생성 성능이 깔끔하고 좋다고 보여진다.(주관적)
코드에 여러가지 feature도 꾸준히 업데이트되고 있으니 관심 있는 분들은 한번 직접 돌려보는 것을 추천한다. (윈도우에서도 돌아감. 대신 해상도에 비례해서 GPU 필요)
이름에서 보듯이 Liquid Warping GAN이라는 기존 기법이 있었는데, 해당 구조에 attention 등을 추가해서 고도화 버전으로 만든 것으로 이해하면 된다.
정의
- 입력된 소수의 이미지의 이미지의의 인물이 타겟 동영상의 인물의 동작을 모사하는 동영상을 생성
대표 논문(Few-shot learning based motion transfer)
- Liquid Warping GAN with attention, Shanghai Tech Univ, Under review of IEEE TPAMI
- Few-shot video to video synthesis, NVIDIA, NeurIPS 2019
- Single-shot Freestyle dance reenactment, Facebook, CVPR 2021
- Few-Shot Human Motion Transfer by Personalized Geometry and Texture Modeling, Huya inc, CVPR 2021
Training Process
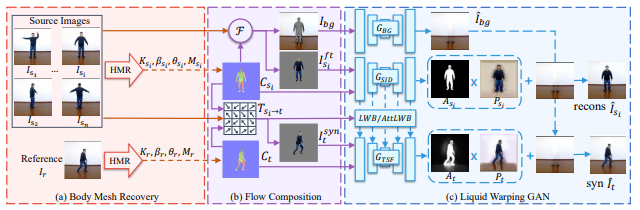
1) Body Mesh Recovery
- Source와 Reference 영상에 대한 3D Pose Estimation(SPIN)

2) Flow Composition
- 1번 과정을 통해 얻은 파라미터들을 이용해서 Source와 Reference에 대한 correspondence map(C)를 얻고, 이를 토앻 Transformation flow T(s -> t)를 계산
- Source 영상을 C에 기반하여 FG/BG로 분리
- T에 기반하여 Source 영상이 전경을 Warping 시켜서 합성영상의 전경 생성
3) Liquid warping GAN
- GBG : BG에 대한 생성(Impainting)
- GSID : Source 영상에 대한 복원을 위한 attention map(A)과 color map(P) 생성

- GTSF : Target 영상에 대한 합성을 위한 attention map(A)과 color map(P) 생성
-> GSID에서 GTSF로 LWB/AttLWB를 통해 학습된 feature를 전달
-> AttLWB : Attention과 SPADE를 통해 기존 LWB보다 multiple source feature를 효율적으로 전달이 가능해짐

Loss Function

- Lp : Perceptual Loss로서 reconstructed source image와 GT와의 차이를 줄이는 방향으로 학습

- Lf : Face Identity Loss로서 크롭된 얼굴에 대해 face identity를 유사하게 하는 방향으로 학습

- Ladv : Adversarial Loss로서 생성 영상의 분포를 GT의 분포와 유사하게 학습

- La : Attention Regularization Loss로서 attention map들을 smooth하게 학습

- Discriminator loss는 다음과 같다


데이터
- 206개 비디오로부터 약 24만여 프레임 추출
- Motion Transfer 학습 시 총 3장 pair로, 앞에 두장은 source image, 한장은 reference image로 이용
Training/Inference
- 전체 데이터로 2 epoch 학습하여 General model 생성
- Inference 시 1/2/4/8개의 이미지(들)에 대해서 100번 fine-tuning(Personalizaiton)하여 reference 영상에 따른 결과물 생성
Demo : Motion Transfer / Novel View Synthesis / Appearance Transfer
https://www.youtube.com/watch?v=I-3au3_i0Vc&ab_channel=WenLiu
https://www.youtube.com/watch?v=th8jcirYQjs&ab_channel=WenLiu
여전히 얼굴 및 복장 합성에 대한 퀄리티 문제가 존재하지만, 현존하는 기법 중에는 few-shot 기반으로 가장 동영상 합성을 잘 하는 기법으로 보인다.
경량화되어 앱 기반으로까지 이어진다면 좀더 각광받을 수 있는 기술이 되지 않을까?
이번 CVPR논문들도 쟁쟁하던데, 잘 읽고 좋은 인사이트들을 많이 배워가야겠다.
참조문헌



