아바타 생성을 다루면서 제일 많이 돌려봤던 기법인 Video to Video Synthesis.
정작 블로그에 제대로 정리한 적은 없어서 간략하게나마 정리해본다고 이렇게 남기게 됐다.
정리하면서 다시 읽어봐도 상당히 거대한 모듈의 결합이고, loss function도 복잡하여 이해하는데 애를 먹었다.
그래도 제대로 Motion Transfer쪽에서 오픈소스화되어 나온 첫 모델이라 생각하고, 학습도 그리 어렵지 않다.
재미로라도 관심있는 분들은(+ 충분히 GPU 자원이 있는) 돌려보는 것을 추천한다.
목적
- 입력 동영상의 인물이 타겟 동영상의 인물의 동작을 모사하는 동영상을 생성
대표 논문
- Video to Video Synthesis, NeurlIPS 2018, NVIDIA (https://github.com/NVIDIA/vid2vid)
- Everybody Dance Now, ICCV 2019, Berkeley AI Research (코드 현재 공개됐음)
Semantic Data(Data Preparation)
- OpenPose(CMU, IEEE TPAMI 2019) : RGB 이미지로부터 사람의 관절 포인트 25개, 얼굴 랜드마크 70개 추출(https://github.com/CMU-Perceptual-Computing-Lab/openpose)
- DensePose(FAIR, CVPR2018) : RGB 이미지의 인간 신체의 픽셀을 3D 맵핑하여 SMPL 기반의 3D 텍스쳐 (Part index + U/V coordinates) 추출 (http://densepose.org/)
구조

- Input : Semantic maps + Past images
- Intermediate : Input을 이용해서 만든 1차 생성 결과물
- Final image = Warp(Past images +Flow map) + Intermediate
Loss Function
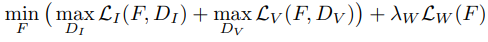
- LI : Image-conditional loss로서, 원본 이미지와 생성 이미지의 차이를 줄이는 방향으로 학습

- LV : Video-conditional loss로서, 동일 optical flow가 주어졌을 때, 생성 비디오와 원본 비디오의 temporal dynamic이 동일해지도록 학습

- LW : flow loss로서 GT와 추정 optical flow가 유사해지도록 Warping 성능 향상

Other Application : edge2face, label2streetview, etc...


Training

- Spatio-temporally Progressive Training
- Spatially progressive : 해상도 점진적으로 증가
- Temporally progressive : 학습에 사용하는 연속 프레임 수 증가
- Alternating training : T증가해서 학습, S 증가해서 학습. 이것을 점진적으로 증가시킴.
Demo
- 학습 데이터 : 3000장 이상의 연속 프레임(동영상)과 그에 따른 전처리 (OpenPose/DensePose)
- 학습 시간 : 최소 이틀 이상. 논문에서는 2K해상도 데이터 학습을 위해 V100 8개로 10일 학습(40epochs)
한계
- 학습 시간(> 2days)과 학습 데이터(> 3000 frames)가 많이 필요함
- 하나의 모델이 한명에 대한 결과만 생성 가능. 즉 아이유 사진으로 학습한 모델에 수지를 넣으면 결과가 안 나옴.
- 결과 생성시 noise처럼 보이는 artifact가 많이 나옴
원체 어려운 motion transfer를 제대로 보여주는 논문이지만 한계도 뚜렷하다.
이후 Few-shot video to video synthesis라는 후속 논문이 나와서 few-shot learning을 이용해서 inference를 간편하게 만들어주지만, general model을 제공하지도 않고 타 논문들에서 비교한 결과들을 봐도 좋은 주관 화질 생성 성능을 보여주지는 않는 것으로 보인다.
이후에는 Few-shot learning을 이용해서 사용성을 보다 편하게 만든 논문을 하나 소개하고자 한다.



